生成式预训练 Transformer(GPT)是现代人工智能中的一个重要突破,驱动了许多尖端的自然语言处理(NLP)应用。
Generative Pre-trained Transformer (GPT) is a significant breakthrough in modern artificial intelligence, driving many cutting-edge applications in natural language processing (NLP).
在本文中,我们将通过更复杂的代码示例、详细的可视化图表,以及对其他 NLP 模型的比较,深入探讨 GPT 的工作原理、局限性及其在实际应用中的潜力。
In this article, we will explore the working principles, limitations, and potential of GPT in practical applications through more complex code examples, detailed visualizations, and comparisons with other NLP models.
引言
Introduction
理解 GPT 及其底层架构 Transformer 对于任何想要深入了解自然语言处理的研究人员和工程师来说都是至关重要的。
Understanding GPT and its underlying Transformer architecture is essential for any researcher or engineer looking to delve into natural language processing.
随着 GPT-4 的发布,它在各个领域的应用更加广泛和深入。
With the release of GPT-4, its applications have become even more widespread and profound across various fields.
什么是 GPT?
What is GPT?
GPT,全称为生成式预训练 Transformer,是一种通过大量数据训练的机器学习模型,能够生成文本、翻译语言、编写创意内容,并与人类进行对话。
GPT, or Generative Pre-trained Transformer, is a machine learning model trained on vast amounts of data, capable of generating text, translating languages, crafting creative content, and engaging in conversations with humans.
以下是 GPT 的核心功能:
Here are the core functionalities of GPT:
- 文本生成:根据输入上下文生成流畅的文本,广泛应用于内容创作。
- Text Generation: Generates coherent text based on input context, widely used in content creation.
- 语言翻译:GPT 能够高效地进行语言翻译,应用于全球沟通。
- Language Translation: GPT efficiently translates languages, facilitating global communication.
- 对话系统:构建智能聊天机器人,进行自然、连贯的对话。
- Dialogue Systems: Builds intelligent chatbots that engage in natural, coherent conversations.
复杂代码示例:生成不同风格的文本
Complex Code Example: Generating Text in Different Styles
python复制代码import openai
# 使用 OpenAI 的 GPT-3 API
# Using OpenAI's GPT-3 API
openai.api_key = 'your-api-key'
def generate_text(prompt, style):
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f"使用{style}风格写一段关于'{prompt}'的文章。",
max_tokens=200
)
return response.choices[0].text.strip()
# 生成不同风格的文本
# Generate text in different styles
formal_text = generate_text("人工智能的未来", "正式")
casual_text = generate_text("人工智能的未来", "非正式")
poetic_text = generate_text("人工智能的未来", "诗意")
print("正式风格:\n", formal_text)
print("\n非正式风格:\n", casual_text)
print("\n诗意风格:\n", poetic_text)
这个示例展示了如何使用 GPT 生成不同风格的文本,例如正式、非正式和诗意风格的文章。
This example demonstrates how to use GPT to generate text in different styles, such as formal, informal, and poetic.
这对于应用 GPT 于具体的内容生成任务非常有用。
This is particularly useful for applying GPT to specific content generation tasks.
Transformer 架构:GPT 的基础
Transformer Architecture: The Foundation of GPT
GPT 的强大功能源于其底层架构——Transformer,这是一种完全基于注意力机制的神经网络架构。
GPT's powerful capabilities stem from its underlying architecture—the Transformer, a neural network architecture entirely based on attention mechanisms.
Transformer 架构图
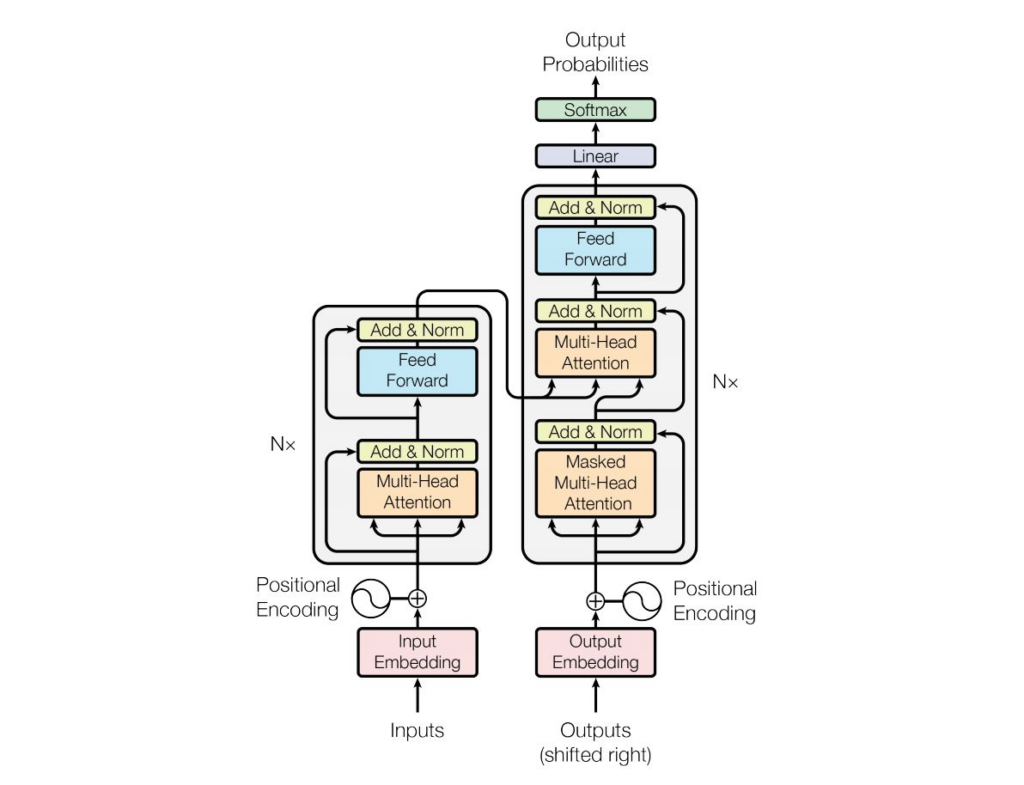
Transformer Working Principle
Transformer的运行原理
1. Input Embedding
1. 输入嵌入
The input text is first broken down into multiple words (or subwords), each of which is converted into a vector representation through an embedding layer.
输入的文本首先被分解为多个词(或子词),每个词通过嵌入层(Embedding Layer)转换为向量表示。
These vectors represent the features of the input words in the model.
这些向量代表了输入词在模型中的特征。
2. Positional Encoding
2. 位置编码
Since the Transformer model does not have built-in sequential information, positional encoding adds positional information to the input vectors.
因为Transformer模型不具有内置的顺序信息,位置编码向输入向量添加了位置信息。
This is achieved by adding the positional encoding vectors to the embedding vectors.
这是通过将位置编码向量与嵌入向量相加来实现的。
3. Multi-Head Attention
3. 多头注意力机制
The core of the encoder and decoder is the multi-head attention mechanism.
编码器和解码器的核心是多头注意力机制。
It allows the model to focus on different parts of the sequence when processing each input word.
它允许模型在处理每个输入词时关注序列中的其他词。
Multi-head attention duplicates the input into multiple different subspaces (heads), applies the attention mechanism independently, and then concatenates the results to form the final output.
多头注意力是通过将输入复制成多个不同的子空间(头),并独立应用注意力机制,然后将结果连接在一起形成最终输出。
This helps the model capture different levels of relevance.
这种方式帮助模型捕捉到不同层次的相关性。
In the decoder, the Masked Multi-Head Attention layer ensures that the model only focuses on the words before the current word to generate the output step by step.
在解码器中,掩码多头注意力 (Masked Multi-Head Attention) 层确保模型只关注当前词之前的词,以便逐步生成输出。
4. Feed Forward Neural Network
4. 前馈神经网络
The output of the multi-head attention mechanism is sent to a feed-forward neural network layer, which processes each position independently.
多头注意力机制的输出被送入前馈神经网络层,每个位置独立处理。
This network layer usually includes two fully connected layers and applies an activation function.
这个网络层通常包括两层全连接网络,并应用激活函数。
This stacked structure helps the model handle more complex features and enhances its expressive power.
这种层叠结构可以帮助模型处理更加复杂的特征,并增强模型的表达能力。
5. Residual Connection and Layer Normalization
5. 残差连接和层归一化
After each multi-head attention and feed-forward neural network, there is a residual connection that adds the input to the output.
每个多头注意力和前馈神经网络之后都有一个残差连接,它将输入与输出相加。
This mechanism helps alleviate the training difficulties of deep models.
这种机制帮助缓解深度模型的训练困难。
Layer normalization is then performed, which makes the training of the model more stable.
然后,进行层归一化(Layer Normalization),这使得模型的训练更加稳定。
6. Decoder Output
6. 解码器的输出
In the decoder part, the model uses the output from the encoder and the attention mechanism in the decoder to generate output predictions.
在解码器部分,模型利用编码器输出和解码器中的注意力机制来生成输出的预测。
The output embedding layer and positional encoding are combined to process the input to the decoder (i.e., the output from the previous time step).
输出嵌入层(Output Embedding)和位置编码相结合,用来处理解码器的输入(即前一个时间步的输出)。
The final layer of the decoder is a fully connected layer that maps the output to a vector of vocabulary size, using the Softmax function to compute the probability of each word.
解码器的最后一层是一个全连接层,将输出映射到词汇表大小的向量上,使用Softmax函数计算每个词的概率。
7. Output Probabilities
7. 输出概率
The last step is through the Softmax layer, which converts the output of the decoder into a probability distribution for the next word.
最后一步是通过Softmax层,将解码器的输出转换为下一个词的概率分布。
The model predicts the next word based on this probability distribution, generating the entire output sequence step by step.
模型根据这个概率分布来预测下一个词,逐步生成整个输出序列。
The Transformer model can efficiently process long sequence data and capture complex dependencies between inputs through this architecture.
Transformer通过这种架构能够高效处理长序列数据,并捕捉到输入之间复杂的依赖关系。
Its multi-head attention mechanism and residual connections make the model perform well in both computational efficiency and learning capability.
其多头注意力机制和残差连接使得模型在计算效率和学习能力上都表现出色。
This makes it one of the most widely used models in current NLP tasks.
这使得它成为当前NLP任务中广泛应用的模型之一。
GPT 的工作原理
How GPT Works
1. 输入文本的标记化
1. Tokenization of Input Text
GPT 首先将输入文本分解为更小的单元,称为“标记”(tokens)。
GPT first breaks down the input text into smaller units called "tokens."
这些标记是文本的基本组成部分,可以是一个词、词的一部分,甚至是一个字符。
These tokens are the basic building blocks of the text and can be a word, a part of a word, or even a character.
2. 嵌入表示
2. Embedding Representation
每个标记通过嵌入矩阵转换为向量表示。
Each token is converted into a vector representation through an embedding matrix.
这些向量捕捉了标记之间的语义关系,使模型能够理解词与词之间的联系。
These vectors capture the semantic relationships between tokens, enabling the model to understand the connections between words.
3. 多层注意力和前馈神经网络
3. Multi-layer Attention and Feedforward Neural Network
向量表示被输入到多个注意力层和前馈神经网络层中。
The vector representations are input into multiple attention layers and feedforward neural network layers.
4. 生成下一个标记
4. Generating the Next Token
经过多层处理后,GPT 模型输出一个概率分布,表示下一个标记的可能性。
After multiple layers of processing, the GPT model outputs a probability distribution representing the likelihood of the next token.
模型根据这个概率分布进行采样,从而生成下一个标记并将其添加到输出序列中。
The model samples from this probability distribution to generate the next token, which is then added to the output sequence.
GPT 的局限性和潜在风险
GPT's Limitations and Potential Risks
虽然 GPT 在许多任务中表现优异,但它也有一些局限性和潜在风险:
While GPT performs excellently in many tasks, it also has some limitations and potential risks:
局限性
Limitations
- 上下文长度限制:GPT 对长文本的处理能力有限,容易丢失远距离上下文信息。
- Context Length Limitation: GPT has limited capacity to handle long texts and may lose track of distant context information.
- 数据依赖:模型的性能强烈依赖于训练数据的质量和多样性,训练数据中的偏见可能会影响输出结果。
- Data Dependence: The model's performance is heavily dependent on the quality and diversity of training data, and biases in the training data may affect the output.
潜在风险
Potential Risks
- 错误信息生成:GPT 有时会生成看似合理但实际上错误的信息,可能误导用户。
- Generation of Misinformation: GPT sometimes generates plausible but actually incorrect information, which may mislead users.
- 滥用风险:GPT 的生成能力可能被用于生成有害内容,如虚假新闻或恶意代码。
- Risk of Misuse: GPT's generation capabilities could be used to create harmful content, such as fake news or malicious code.
与其他 NLP 模型的对比
Comparison with Other NLP Models
与其他 NLP 模型相比,GPT 具有一些独特的优势:
Compared to other NLP models, GPT has some unique advantages:
GPT vs BERT
GPT vs BERT
- 生成能力:GPT 是生成模型,可以生成连续文本,而 BERT 是一个编码模型,主要用于文本理解。
- Generative Ability: GPT is a generative model capable of producing continuous text, whereas BERT is an encoding model mainly used for text understanding.
- 模型架构:BERT 使用双向 Transformer 编码器,而 GPT 使用单向解码器。
- Model Architecture: BERT uses a bidirectional Transformer encoder, while GPT uses a unidirectional decoder.
GPT vs T5
GPT vs T5
- 任务通用性:T5 采用“文本到文本”的通用框架,而 GPT 更专注于生成任务。
- Task Generalization: T5 adopts a "text-to-text" framework, while GPT is more focused on generative tasks.
- 性能:在某些生成任务上,GPT 的性能优于 T5,但在理解任务上可能略逊一筹。
- Performance: GPT outperforms T5 in certain generative tasks but may be slightly less effective in understanding tasks.