Deep Dive into Transformer: The Charm of Attention Mechanism
深入浅出Transformer:注意力机制的魅力
The Transformer model has revolutionized the field of natural language processing, with its core being the attention mechanism. This article will take you on a deep dive into the attention mechanism in Transformer, unveiling its principles and charm. Transformer模型在自然语言处理领域掀起了一场革命,其核心在于注意力机制。这篇文章将带你深入了解Transformer中的注意力机制,揭开其背后的原理和魅力。
What is the Attention Mechanism?
什么是注意力机制?
The attention mechanism, simply put, allows the model to selectively focus on the most important parts of the input sequence when processing information. Imagine when you’re reading an article, you naturally focus your attention on key words and topic sentences, while ignoring some less important details. The attention mechanism simulates this human cognitive process. 注意力机制,简单来说,就是让模型在处理信息时,能够有选择地关注输入序列中最重要的部分。想象一下,你在阅读一篇文章时,会自然而然地将注意力集中在关键词、主题句上,而忽略掉一些不重要的细节。注意力机制正是模拟了这种人类的认知过程。
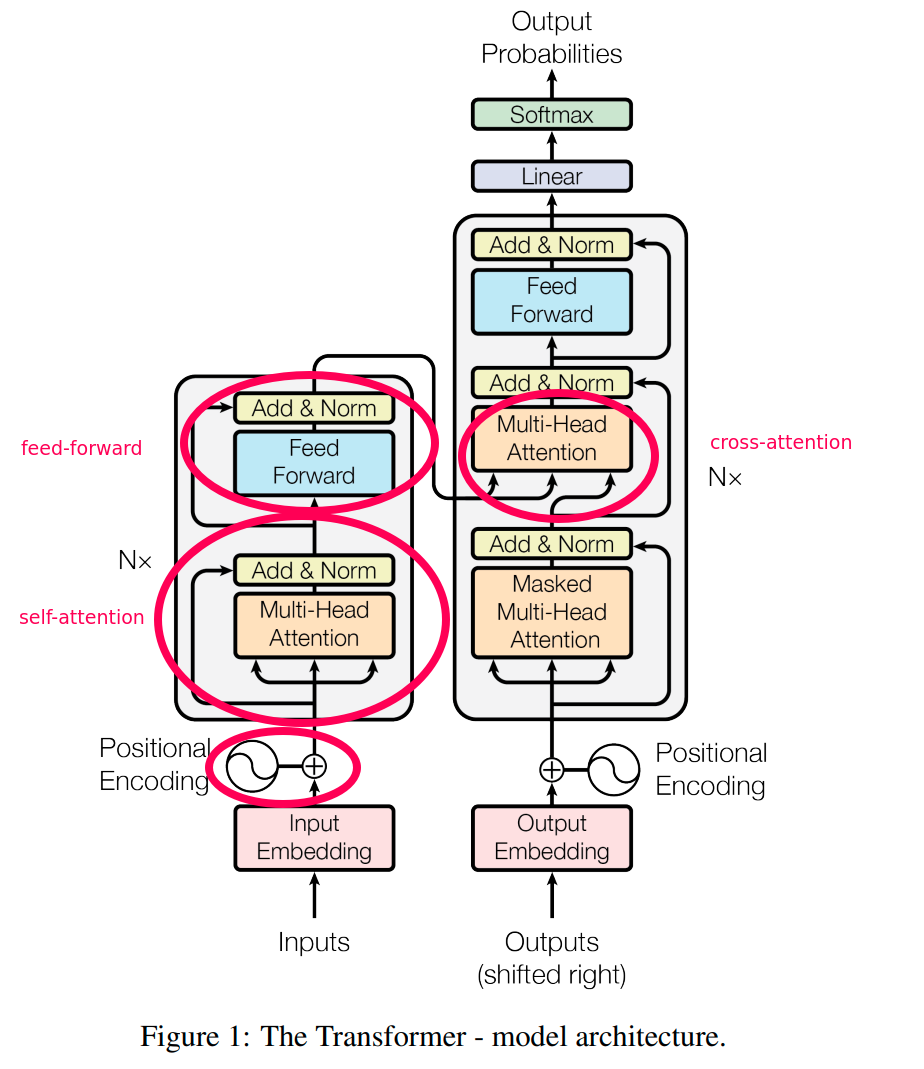

Attention Mechanism in Transformer
Transformer中的注意力机制
In Transformer, the attention mechanism is used to calculate the degree of influence of each word in the input sequence on other words. Through this method, the model can better capture long-distance dependencies between words, thus more accurately understanding the meaning of the text. 在Transformer中,注意力机制被用来计算输入序列中每个单词对其他单词的影响程度。通过这种方式,模型可以更好地捕捉单词之间的长距离依赖关系,从而更准确地理解文本的含义。
How the Attention Mechanism Works
注意力机制的工作原理
Let’s explain the working principle of the attention mechanism step by step, and explain in detail the technical terms in each step: 让我们一步步解释注意力机制的工作原理,并详细解释每个步骤中的专业术语:
-
Input Embedding:
-
输入嵌入:
-
What is input embedding? Input embedding is the process of converting words into a numerical form that computers can understand.
-
什么是输入嵌入?输入嵌入是将单词转换成计算机可以理解的数字形式。
-
Specific method: We assign a unique list of numbers (also called a vector) to each word. This vector usually has several hundred numbers, each number representing a certain feature of this word.
-
具体做法:我们给每个单词分配一个独特的数字列表(也叫向量)。这个向量通常有几百个数字,每个数字代表这个单词的某个特征。
-
For example: Suppose the vector for the word “cat” is [0.1, 0.3, -0.2, …], the vector for “dog” might be [0.2, 0.1, 0.1, …]. These numbers reflect the relationships between words, for example, the vectors for “cat” and “dog” would be more similar than the vectors for “cat” and “table”.
-
举个例子:假设"猫"这个词的向量是[0.1, 0.3, -0.2, …],"狗"的向量可能是[0.2, 0.1, 0.1, …]。这些数字反映了单词之间的关系,比如"猫"和"狗"的向量会比"猫"和"桌子"的向量更相似。
-
-
Calculating Attention Scores:
-
计算注意力分数:
-
What are attention scores? Attention scores represent how important one word is for understanding another word.
-
什么是注意力分数?注意力分数表示一个单词对于理解另一个单词有多重要。
-
How to calculate: For every pair of words in the sentence, we calculate their “similarity”. This similarity is the attention score.
-
如何计算:对于句子中的每一对单词,我们计算它们之间的"相似度"。这个相似度就是注意力分数。
-
For example: In the sentence “I like to eat apples”, for understanding the word “eat”, “apples” might have a very high attention score, while “I” might have a lower score.
-
举个例子:在"我喜欢吃苹果"这句话中,对于理解"吃"这个词,"苹果"可能会有很高的注意力分数,而"我"的分数可能就低一些。
-
-
Calculating Attention Weights:
-
计算注意力权重:
-
What are attention weights? Attention weights are the attention scores converted into percentage form, making their sum equal to 100%.
-
什么是注意力权重?注意力权重是将注意力分数转换成百分比形式,使它们的总和等于100%。
-
How to calculate: We use a mathematical function called “softmax”. This function can convert any group of numbers into a group of positive numbers that add up to 1.
-
如何计算:我们使用一个叫做"softmax"的数学函数。这个函数可以把任何一组数字转换成一组相加等于1的正数。
-
Why do this? This makes it easier for the model to understand the relative importance of each word.
-
为什么要这样做?这样可以让模型更容易理解每个单词的相对重要性。
-
-
Calculating Weighted Sum:
-
计算加权和:
-
What is a weighted sum? The weighted sum is the result of combining the information of each word according to its importance (weight).
-
什么是加权和?加权和是将每个单词的信息按照其重要性(权重)组合在一起的结果。
-
How to calculate: For each word, we multiply its vector by the corresponding attention weight, then add all the results together.
-
如何计算:对于每个单词,我们将其向量乘以对应的注意力权重,然后把所有结果加在一起。
-
What does the result mean? The final new vector contains the information of the original word, but more reflects the features of important words.
-
结果意味着什么?最终得到的新向量包含了原始单词的信息,但更多地体现了重要单词的特征。
-
Multi-Head Attention Mechanism
多头注意力机制
Multi-head attention mechanism is an important innovation in the Transformer model. Let’s understand its origin, background, and technical challenges: 多头注意力机制是Transformer模型中的一个重要创新。让我们来了解它的由来、背景和技术难点:
-
Origin and Background:
-
由来和背景:
-
Limitations of single attention mechanism: Researchers found that a single attention mechanism might not be able to capture all important relationships in the text. Just like humans understand a passage by thinking from multiple angles.
-
单一注意力机制的局限性:研究人员发现,单一的注意力机制可能无法捕捉到文本中的所有重要关系。就像人类在理解一段话时,会从多个角度来思考一样。
-
Source of inspiration: This idea partly comes from the field of computer vision, where models often use multiple “convolution kernels” to capture different features of an image.
-
灵感来源:这个想法部分来自于计算机视觉领域,那里的模型常常使用多个"卷积核"来捕捉图像的不同特征。
-
-
How Multi-Head Attention Works:
-
多头注意力的工作原理:
-
What is a “head”? Each “head” is like an independent attention calculation unit that can focus on different aspects of the input.
-
什么是"头"?每个"头"就像是一个独立的注意力计算单元,可以关注输入的不同方面。
-
Parallel computation: Multiple heads work simultaneously, each head performing the attention calculation process described above.
-
并行计算:多个头同时工作,每个头都执行上面描述的注意力计算过程。
-
Information integration: Finally, we combine the outputs of all heads to get the final result.
-
信息整合:最后,我们将所有头的输出组合起来,得到最终的结果。
-
-
Technical Challenges and Solutions:
-
技术难点和解决方案:
-
Computational complexity: Multiple heads mean more computation, which may lead to longer training time.
-
计算复杂度:多个头意味着更多的计算,这可能导致训练时间变长。 Solution: Researchers mitigate this problem through parallel computing and optimized algorithms. 解决方案:研究人员通过并行计算和优化算法来缓解这个问题。
-
Increased number of parameters: More heads mean more parameters to learn.
-
参数数量增加:更多的头意味着更多的参数需要学习。 Solution: Use parameter sharing techniques and carefully design the dimensions of each head to control the total number of parameters. 解决方案:使用参数共享技术,并仔细设计每个头的维度,以控制总参数数量。
-
How to determine the optimal number of heads: There are no fixed rules to decide how many heads should be used.
-
如何确定最佳的头数:没有固定的规则来决定应该使用多少个头。 Solution: Determine through experiments and experience, usually between 4 and 16. 解决方案:通过实验和经验来确定,通常在4到16之间。
-
-
Advantages of Multi-Head Attention:
-
多头注意力的优势:
-
Capturing diverse features: Different heads can learn to focus on different types of information, such as grammatical relationships, semantic similarities, etc.
-
捕捉多样化的特征:不同的头可以学习关注不同类型的信息,比如语法关系、语义相似性等。
-
Enhancing model robustness: Multiple heads provide multi-angle information, making the model less likely to be affected by noise from a single perspective.
-
增强模型的鲁棒性:多个头提供了多角度的信息,使模型不容易被单一视角的噪声影响。
-
Improving expressiveness: Allows the model to consider information from multiple levels simultaneously, improving its ability to understand complex language phenomena.
-
提高表现力:允许模型同时考虑多个层面的信息,提高了对复杂语言现象的理解能力。
-
Through the multi-head attention mechanism, the Transformer model can understand the input text more comprehensively and in detail, which is also a key reason for its excellent performance in various natural language processing tasks. 通过多头注意力机制,Transformer模型能够更全面、更细致地理解输入的文本,这也是它在各种自然语言处理任务中表现出色的关键原因之一。

Code Example: Simple Self-Attention Mechanism Implementation
代码示例:简单的自注意力机制实现
Here’s a code example implementing a simple self-attention mechanism using Python and NumPy library. We’ll explain each part’s function step by step: 以下是一个使用Python和NumPy库实现简单自注意力机制的代码示例。我们会逐步解释每一部分的功能:
import numpy as np
def simple_attention(query, key, value):
# Calculate attention scores
# 计算注意力分数
scores = np.dot(query, key.T)
# Convert scores to probability distribution
# 将分数转换为概率分布
attention_weights = softmax(scores)
# Calculate weighted sum
# 计算加权和
output = np.dot(attention_weights, value)
return output, attention_weights
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
# Example usage
# 示例使用
sequence_length = 4
embedding_dim = 3
# Randomly generate some sample data
# 随机生成一些示例数据
query = np.random.rand(sequence_length, embedding_dim)
key = np.random.rand(sequence_length, embedding_dim)
value = np.random.rand(sequence_length, embedding_dim)
output, weights = simple_attention(query, key, value)
print("Attention weights:")
print("注意力权重:")
print(weights)
print("\nOutput:")
print("\n输出:")
print(output)
This simplified implementation demonstrates the core idea of the attention mechanism. In actual Transformer models, there would be more details and optimizations. 这个简化的实现展示了注意力机制的核心思想。在实际的Transformer模型中,还会有更多的细节和优化。
Summary
总结
The attention mechanism, especially the multi-head attention mechanism, is the core of the Transformer model, endowing the model with the ability to understand complex language relationships. By allowing the model to flexibly focus on different parts of the input, Transformer can capture long-distance dependencies and subtle language features, which is difficult for traditional models to achieve. 注意力机制,特别是多头注意力机制,是Transformer模型的核心,它赋予了模型理解复杂语言关系的能力。通过允许模型灵活地关注输入的不同部分,Transformer能够捕捉到长距离依赖和细微的语言特征,这是传统模型难以做到的。